Short Notes: TCP Flow and Congestion Control
Controlling traffic through the routers at large
TCP Flow Control
Flow control deals with the amount of data sent to the receiver side without receiving any acknowledgment. It makes sure that the receiver will not be overwhelmed with data. The data link layer in the OSI model is responsible for facilitating flow control. The goal of flow control is to prevent buffer overflow, which can lead to dropped packets and poor network performance.
The flow control mechanism tells the sender the maximum speed at which the data can be sent to the receiver device. The sender adjusts the speed as per the receiver’s capacity to reduce the frame loss from the receiver side. Flow control in TCP ensures that it’ll not send more data to the receiver in the case when the receiver buffer is already completely filled. The receiver buffer indicates the capacity of the receiver.
TCP flow control works by using a sliding window protocol, which means that the sender and the receiver maintain a window of bytes that indicates how much data can be sent or received at any given time. TCP flow control is needed to prevent buffer overflow and underflow at the receiver’s end.
The main parameters that affect TCP flow control are maximum segment size (MSS), initial window size (IWS), and window scaling factor (WSF).
- MSS is negotiated by sender and receiver during connection establishment based on the minimum MTU of the network path.
- IWS affects how fast data transmission can start and how quickly the window can grow.
- WSF enables TCP to handle large BDP networks by allowing window size to exceed 16-bit limit up to
2^30 bytes. It is negotiated by sender and receiver based on their capabilities and preferences.
TCP flow control has several benefits:
- It prevents buffer overflow and underflow, which can cause packet loss, retransmission, and wasted resources.
- It adapts to the network conditions and the receiver’s buffer availability, allowing the sender to use the available bandwidth without starving other flows or creating congestion.
TCP Congestion Control
Broadly speaking, the idea of TCP congestion control is for each source to determine how much capacity is available in the network, so that it knows how many packets it can safely have in transit. It is a technique used to prevent congestion in a network. Congestion occurs when too much data is being sent over a network, and the network becomes overloaded, leading to dropped packets and poor network performance.
Once a given source has packets in transit, it uses the arrival of an ACK as a signal that one of its packets has left the network and that it is therefore safe to insert a new packet into the network without adding to the level of congestion. By using ACKs to pace the transmission of packets, TCP is said to be “self-clocking”.
Congestion control prevents network congestion by regulating the rate at which data is sent from the sender to the receiver. It helps in efficient use of network resources by reducing the number of lost packets and retransmissions. It also ensures a fair allocation of network resources by regulating the rate of data flow for all sources.
Stratergies in use
Additive Increase/Multiplicative Decrease
- TCP maintains a new state variable for each connection, called
CongestionWindow, which is used by the source to limit how much data it is allowed to have in transit at a given time. - AIMD combines linear growth of the congestion window when there is no congestion with an exponential reduction when congestion is detected.
- The approach taken is to increase the transmission rate (window size), probing for usable bandwidth, until loss occurs. The policy of additive increase may, for instance, increase the congestion window by a fixed amount every round-trip time.
- When congestion is detected, the transmitter decreases the transmission rate by a multiplicative factor. For example, the source sets
CongestionWindowto half of its previous value after loss.
- This pattern of continually increasing and decreasing the congestion window continues throughout the lifetime of the connection. In fact, if you plot the current value of
CongestionWindowas a function of time, you get a sawtooth pattern.
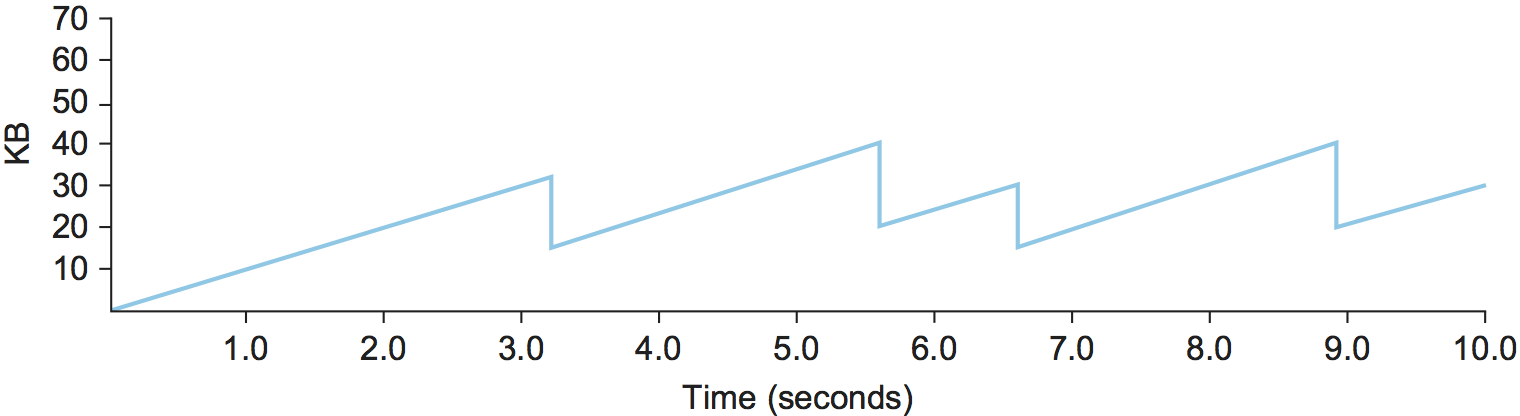
- An intuitive explanation for why TCP decreases the window aggressively and increases it conservatively is that the consequences of having too large a window are compounding. This is because when the window is too large, packets that are dropped will be retransmitted, making congestion even worse. It is important to get out of this state quickly.
TCP Slow Start
-
AIMD takes too long to ramp up a connection when it is starting from scratch and on a bigger capacity network. TCP therefore provides a second mechanism, ironically called slow start, which is used to increase the congestion window rapidly from a cold start. Slow start effectively increases the congestion window exponentially, rather than linearly. TCP effectively doubles the number of packets it has in transit every RTT.
-
Why any exponential mechanism would be called “slow” is puzzling at first, but it can be explained if put in the proper historical context. We need to compare slow start not against the linear mechanism of the previous subsection, but against the original behavior of TCP. If the source sends as many packets as the advertised window allows, which is exactly what TCP did before slow start was developed, then even if there is a fairly large amount of bandwidth available in the network, the routers may not be able to consume this burst of packets. It all depends on how much buffer space is available at the routers.
-
Slow start was therefore designed to space packets out so that this burst does not occur. In other words, even though its exponential growth is faster than linear growth, slow start is much “slower” than sending an entire advertised window’s worth of data all at once.
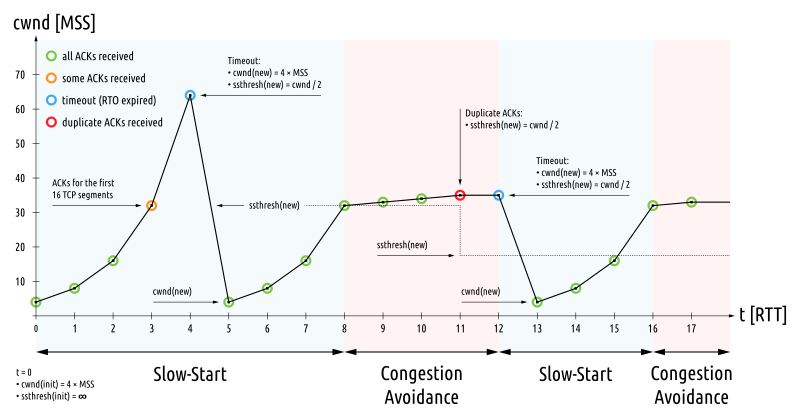
The transmission rate will be increased by the slow-start algorithm until either a packet loss is detected, the receiver’s advertised window (rwnd) becomes the limiting factor, or slow start threshold (ssthresh) is reached, which is used to determine whether the slow start or congestion avoidance algorithm is used, a value set to limit slow start.
If the CWND reaches ssthresh, TCP switches to the congestion avoidance algorithm. It should be increased by up to 1 MSS for each RTT. A common formula is that each new ACK increases the CWND by MSS * MSS / CWND. It increases almost linearly and provides an acceptable approximation.
If a loss event occurs, TCP assumes that it is due to network congestion and takes steps to reduce the offered load on the network. These measures depend on the exact TCP congestion avoidance algorithm used.
When a TCP sender detects segment loss using the retransmission timer and the given segment has not yet been resent, the value of ssthresh must be set to no more than half of the amount of data that has been sent but not yet cumulatively acknowledged or 2 * MSS, whichever value is greater.
TCP Tahoe: When a loss occurs, retransmit is sent, half of the current CWND is saved as ssthresh and slow start begins again from its initial CWND.
TCP Reno: A fast retransmit is sent, half of the current CWND is saved as ssthresh and as new CWND, thus skipping slow start and going directly to the congestion avoidance algorithm. The overall algorithm here is called fast recovery.
TCP Fast retransmit
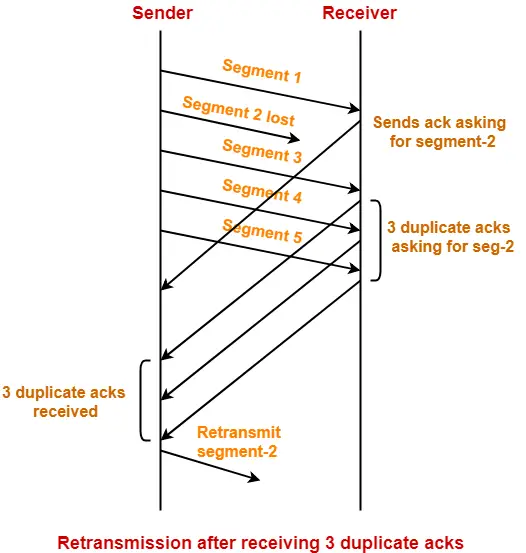
Fast retransmit is an enhancement to TCP that reduces the time a sender waits before retransmitting a lost segment. If an acknowledgment is not received for a particular segment within a specified time (a function of the estimated round-trip delay time), the sender will assume the segment was lost in the network and will retransmit the segment.
Duplicate acknowledgment is the basis for the fast retransmit mechanism. After receiving a packet an acknowledgement is sent for the last in-order byte of data received. When a sender receives three duplicate acknowledgments, it can be reasonably confident that the segment carrying the data that followed the last in-order byte specified in the acknowledgment was lost. A sender with fast retransmit will then retransmit this packet immediately without waiting for its timeout.
TCP Cubic
It is variant of the standard TCP algorithm, and is the default congestion control algorithm distributed with Linux. CUBIC’s primary goal is to support networks with large delay X bandwidth products, which are sometimes called long-fat networks. Such networks suffer from the original TCP algorithm requiring too many round-trips to reach the available capacity of the end-to-end path. CUBIC does this by being more aggressive in how it increases the window size, but of course the trick is to be more aggressive without being so aggressive as to adversely affect other flows.
One important aspect of CUBIC’s approach is to adjust its congestion window at regular intervals, based on the amount of time that has elapsed since the last congestion event (e.g., the arrival of a duplicate ACK), rather than only when ACKs arrive (the latter being a function of RTT). This allows CUBIC to behave fairly when competing with short-RTT flows, which will have ACKs arriving more frequently.
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email